Privacy
Privacy-First Engineering: The Case for On-Device AI
Why we prefer local processing over cloud pipelines whenever the job can be done safely and well on the user's own device.
Why we start from the device
A lot of modern software treats the network as the default place where intelligence lives. Cloud APIs are convenient, capable, and easy to integrate. The result is that data flows outward by default — to classification services, to recommendation engines, to usage pipelines — without always asking whether any of that transmission is strictly necessary.
Our starting assumption is narrower: if the device already has the context it needs, the device should do the work. That premise changes the architecture in ways that go beyond a privacy policy claim. It affects what data is collected, what fails when connectivity is poor, and what happens to the product if the back-end service changes.
On-device processing is not appropriate for every feature. Some jobs require synchronization, shared state, or external computation that cannot reasonably be replicated locally. But a lot of features that currently run in the cloud do not need to, and the habit of reaching for a cloud API first has hidden costs that are easy to overlook when you are building the first version.
The trust model shifts when the server is removed
When a feature runs on a cloud server, the privacy model requires trusting the vendor's policies, the vendor's security practices, the vendor's business continuity, and whatever the vendor decides to do with collected data in the future. Those are real dependencies, even when the current policy is favorable.
When the same feature runs on the user's device, the trust model is simpler. The data does not leave the device. There is no server-side log of what was processed. There is no API key that could be leaked or misused. The user's privacy posture does not change if the vendor is acquired, pivots, or is breached.
For small independent developers, there is also a practical advantage: eliminating a cloud processing dependency means eliminating a recurring infrastructure cost and a class of operational failure. A feature that runs locally cannot have a server outage. It cannot be throttled by API rate limits. It cannot be suddenly deprecated by a third-party service.
What Apple's on-device frameworks enable
Apple's Natural Language framework provides text classification, language detection, named entity recognition, and semantic similarity comparison — all running on the device using Core ML. These are not toy capabilities. They are the same class of NLP operations that would otherwise require an API call to an external service.
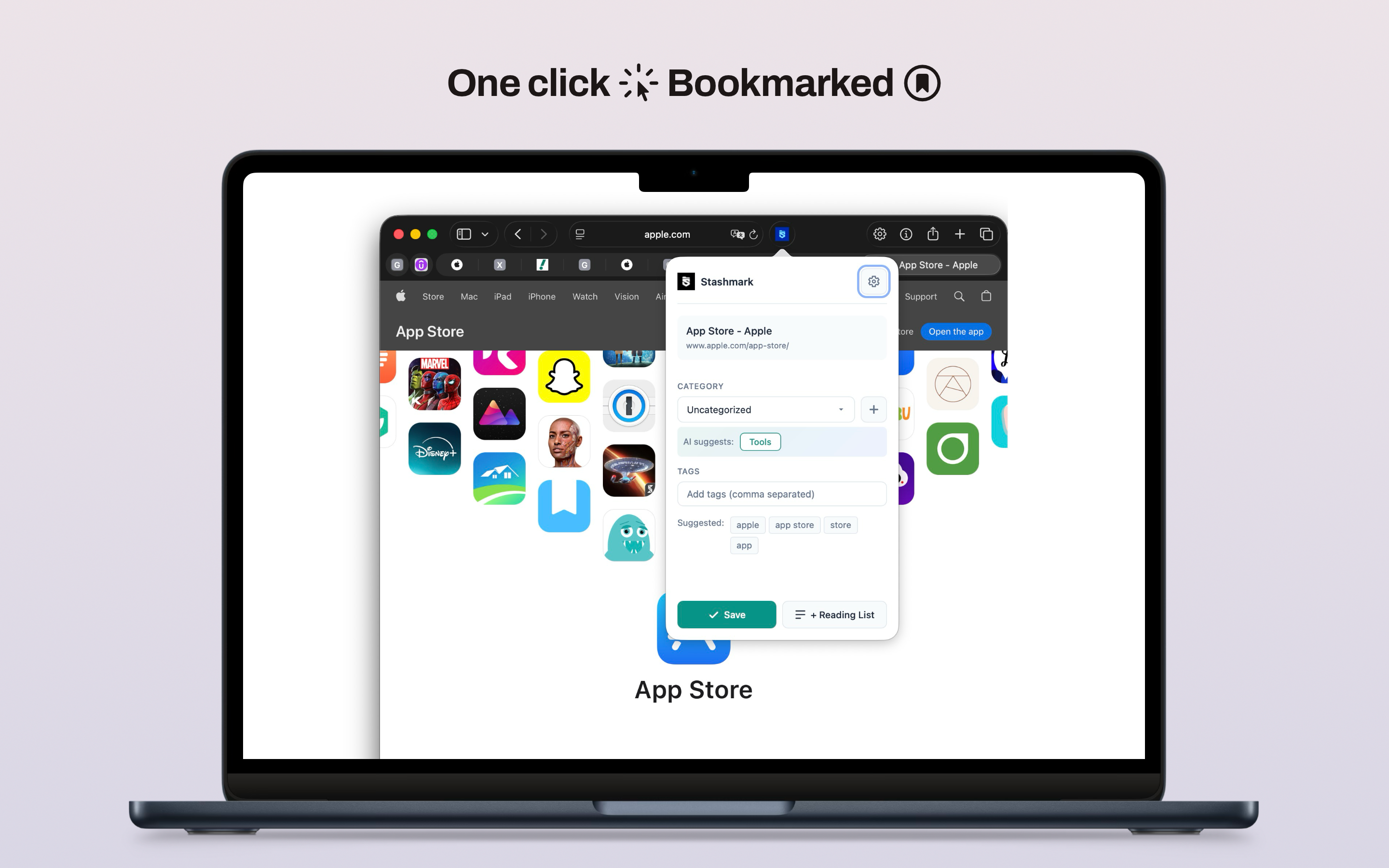
For Stashmark's link categorization feature, the framework reads the page title and URL, classifies the content type, and suggests a category. That classification happens in milliseconds, with no network latency, no account authentication, and no data transmission. The result is not meaningfully less accurate than a cloud-based approach for the task it is solving.
Core ML also allows developers to ship custom models trained on specific datasets as part of the app bundle. The model runs on the Neural Engine in Apple Silicon devices, which is optimized for this kind of inference workload and consumes very little battery in the process. The performance gap between on-device and cloud inference has narrowed significantly as device hardware has improved.
Stashmark as a practical example
Stashmark helps people save links without turning their bookmark list into a landfill. The interesting part is the categorization step. Instead of sending saved links to a remote classification service, Stashmark uses Apple's Natural Language framework to suggest categories locally.
That changes the trust model in a concrete way. The saved URL does not need to pass through a third-party AI API. There is no account system required to make the feature work. The extension communicates with the companion app on the same Mac — there is no intermediate network hop where browsing context could be intercepted or logged.
The result is not just a privacy policy claim — it is a simpler product architecture. Fewer moving parts means fewer ways the feature can break. The categorization works on an airplane. It works when the API of a hypothetical remote service has a rate-limiting event. It works the same way on day one as it does after five years of use.
Sahibinden Araç Analizi follows the same rule
The same principle applies to Sahibinden Araç Analizi. The extension reads listing details in the browser, matches them against a local knowledge base of vehicle reliability data, and highlights known chronic issues and risk signals directly in the page.
That is important because the task is sensitive. Marketplace browsing behavior — which listings you view, how long you spend on each, what price ranges you focus on — describes a purchasing intent profile that has commercial value. Most buyers would not want that kind of data flowing to a remote service if the product can avoid it.
The knowledge base is bundled with the extension and updated through normal extension updates. The analysis is never dependent on a network call completing, which also means it appears immediately when the page loads rather than after a loading delay while waiting for a server response.
Performance as a side effect of local processing
One often-overlooked benefit of on-device processing is latency. A cloud API call adds round-trip time, variable based on network conditions and server load, to any feature that depends on it. For features that need to feel instant — a save action in a browser extension, an analysis appearing when a page loads — that latency is a user experience problem, not just a theoretical one.
On-device inference is fast. The Neural Engine on an M-series Mac can run a classification model in single-digit milliseconds. From the user's perspective, the feature appears instantaneous. That is not a minor quality-of-life difference — it is the difference between a feature that feels native and one that feels like it is waiting for something.
For a product philosophy built around native behavior and removing friction, that responsiveness is as important as the privacy story. The two benefits reinforce each other. The architecture that makes the product more private also makes it feel faster.
When cloud is still the right answer
On-device processing is not a universal answer. Some features genuinely require server-side computation, synchronization across multiple users, or capabilities that device hardware cannot support at acceptable quality levels. The principle is not to avoid the cloud on ideological grounds — it is to reach for it only where it adds clear value over local processing.
A good test is to ask what the user is actually handing over when a feature requires a network call. If the data being transmitted is personal, sensitive, or commercially valuable, and the cloud is not providing something that cannot be done locally, the case for keeping it on device is strong.
We try to use the network where it adds unambiguous value: syncing data across devices through the user's own CloudKit account, distributing app updates, processing payments. For everything that can run locally and still do the job well, we keep it local. That discipline keeps the software easier to trust, easier to explain, and usually faster to use.